





Why Big Data may not be Very Big: The D’s and the V’s

Why Big Data may not be Very Big: The D’s and the V’s
Why Big Data may not be Very Big: The D’s and the V’s
Most people interested in big data know about the “V”s but do you know the “D”s?
Big Data “V”s depend on who defines them. IBM is fond of a 4 “V” definition (Volume, Velocity, Variety, and Veracity). Others have 10 or more “V”s. These might include Variability, Vulnerability. These are all important, and all worthy of consideration.
We’d suggest there are some “D”’s worth considering as well. They help explain why a data lake might be much shallower than it seems.
Dirty – Most data sets are dirty. People who do this for a living have some funny stories about this. The human who entered the wrong data in a field. The software nanny on a quest to purge personal information that deleted all 9 digit numbers thinking they were Social Security Numbers, the data logger that is sending information in the wrong units. Whether the issue is bad data or missing data, all dirty data distorts. It is the bane of data science https://www.forbes.com/sites/gilpress/2016/03/23/data-preparation-most-time-consuming-least-enjoyable-data-science-task-survey-says/#1c874e736f63
Drifting – At a drilling conference, a presenter showed a scatter plot on the use of frac sand, which had a weak trend over many wells completed. But, with some teasing, stronger trends come out. For example, this chart shows that over time, well depth is getting deeper. The early wells are not the same as the new wells. The ‘typical’ well has been drifting.

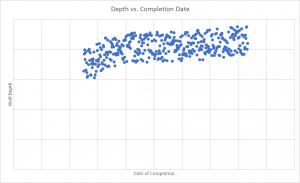
There are all kinds of reasons for drift. Often, drift comes from human preferences, and learning, which may be some of the causes of the drilling trend. At some point, the drift has taken things so far, that we can no longer make “apples to apples” comparisons.
Doubtful – There are many reasons to doubt the validity, accuracy, or credibility of data. In addition to the other issues on this list, one often can’t shake the feeling there is something not quite right. Doubtful data often turns out to be compromised (like the “dirty” examples). But doubtful data may have been collected with missing provenance.
Duplicative – Large numbers of records can be impressive until it turns out there is not much going on. This is a problem in the Industrial Internet of Things (IIoT). Think about the temperature reports from a smart thermostat; 74, 74, 74…. 74… 74. The most common duplicative number is zero. There was nothing to report, nothing to report…
Discontinuous – Real data has gaps. The line went dead. The data logger failed. The point of sale went to paper copies in a power outage. Those gaps tend to happen at very interesting times. When we ignore this, we fall prey to selection bias. The gaps can be the most interesting data, but we don’t have it.
Differing Reporting – When we want to do regression analysis, we are limited to the lowest rate of reporting. If we have five variables, it may not matter that one of them is available every second. One of them may only be available once a year. This is like a convoy limited to the speed of the slowest ship.
What does all this mean?
It means data lakes are at risk of not being “big.” Instead, they may not be very big at all. They are shallow, and in some cases, just swamps.
Lone Star recently did an engagement which required machine learning about 30 data sets. These represented several billion individual transactions. But when we were done, we had only about 300 usable data points.
Why was there a reduction on the order of 1,000,000? After reading this, you know, don’t you?
The list above explains most of the issues we see. These also help explain why Lone Star has several techniques to work around these problems and provide truly actionable models. So, you don’t have to drain the swamp; and, you may need far less data that you think.
And, the next time you hear about the “V”’s of Big Data, think about the “D”’s as well; Dirty, Drifting, Doubtful, Duplicative, Discontinuous, and, with Differing Reporting.
About Lone Star Analysis
Lone Star Analysis enables customers to make insightful decisions faster than their competitors. We are a predictive guide bridging the gap between data and action. Prescient insights support confident decisions for customers in Oil & Gas, Transportation & Logistics, Industrial Products & Services, Aerospace & Defense, and the Public Sector.
Lone Star delivers fast time to value supporting customers planning and on-going management needs. Utilizing our TruNavigator® software platform, Lone Star brings proven modeling tools and analysis that improve customers top line, by winning more business, and improve the bottom line, by quickly enabling operational efficiency, cost reduction, and performance improvement. Our trusted AnalyticsOSSM software solutions support our customers real-time predictive analytics needs when continuous operational performance optimization, cost minimization, safety improvement, and risk reduction are important.
Headquartered in Dallas, Texas, Lone Star is found on the web at http://www.Lone-Star.com.